


















































Herausfinden, warum etwas nicht so funktioniert wie gewünscht – das ist eine der größten Herausforderungen, vor der IT-Fachleute, Software-Entwicklung und IT-Sicherheitsspezialisten stehen. Diese Aufgabe zu erfüllen, wird immer schwieriger, insbesondere dann, wenn Echtzeitdaten über ein Netzwerk übertragen werden. Sowohl im privaten als auch im professionellen Bereich hat sich die Zahl von solchen zeitkritischen Anwendungen deutlich erhöht.

Ein Beispiel ist das Streamen von Multimedia-Content. Nutzer erwarten hier angesichts immer höherer Abonnementgebühren, dass die Anbieter solcher Services Inhalte in optimaler Qualität auf ihr Endgerät bringen. Wenn nicht, sind 90 Prozent bereit, den Anbieter zu wechseln. Rund 69 Prozent würden das umgehend tun, wenn bei einem Online-Videodienst mehrfach Ausfälle auftreten. Das sind Ergebnisse einer Studie, die Ende 2023 Accedo in Zusammenarbeit mit New Relic durchführen ließ. Accedo hat sich auf Services und Produkte spezialisiert, mit denen Streaming-Anbieter Content „Over the Top“ (OTT) über das Internet zum Kunden transportieren. New Relic wiederum hat eine Observability-Plattform entwickelt, die auch Accedo nutzt.
Und natürlich erwarten auch Mitarbeiter von Unternehmen, die Videokonferenzsysteme und Collaboration-Tools wie Teams oder Zoom einsetzen, eine hohe Qualität. Dasselbe gilt für Nutzer von unternehmensinternen und externen E-Learning-Angeboten, etwa auf Basis von WebRTC.
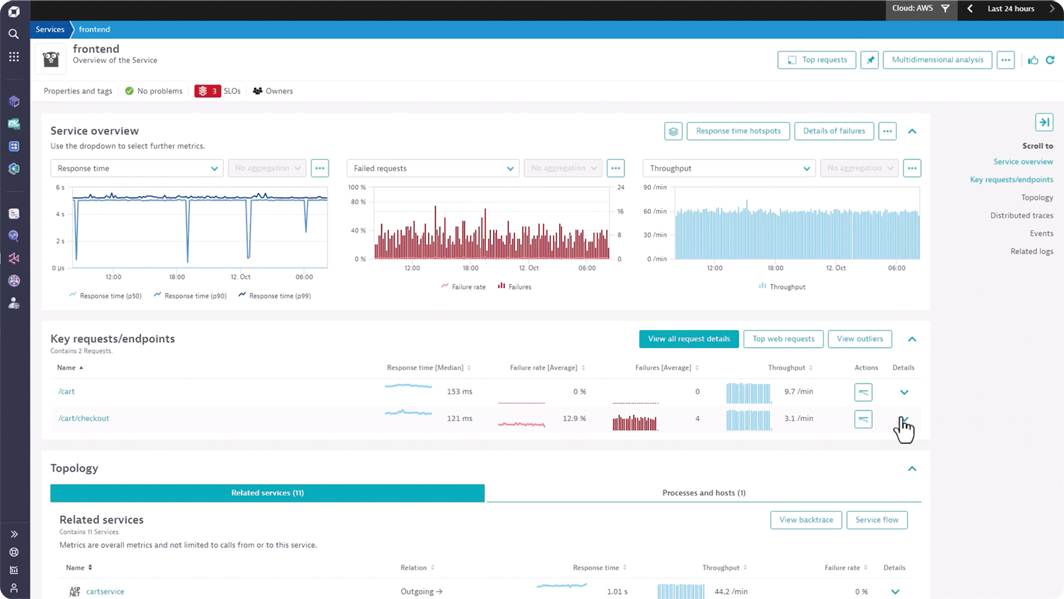
Transparenz durch Observability
Hier kommt Observability ins Spiel. Der Begriff „Beobachtbarkeit“ stammt ursprünglich aus der Steuerungs- und Kontrolltheorie. Er besagt, dass sich der interne Zustand eines komplexen Systems, etwa des automatischen Getriebes eines Fahrzeugs, anhand seines Verhaltens nach „außen“ ermitteln lässt.
Dieser Ansatz lässt sich auf die Informationstechnik übertragen: „Observability ist die Fähigkeit, den Zustand komplexer IT-Systeme auf der Basis vielfältiger Systemdaten zu erfassen und zu analysieren“, erklärt Roman Spitzbart, Vice President Solutions Engineering EMEA bei Dynatrace, einem Anbieter einer Observability-Plattform. „Während sich das herkömmliche Monitoring auf vordefinierte Metriken und erwartete Probleme konzentriert, ermöglicht Observability eine dynamische und tiefgreifende Untersuchung des gesamten IT-Ökosystems“, so Spitzbart weiter.
Solche detaillierten Analysen sind nötig, weil IT-Infrastrukturen und Anwendungsumgebungen komplexer werden. Dazu tragen Hybrid- und Multi-Clouds, Container-Techniken wie Kubernetes und Docker sowie Microservices und Serverless-Funktionen bei. Hinzu kommen Praktiken beim Entwickeln, Bereitstellen und Absichern von Software, beispielsweise agile Entwicklung, Continuous Integration und Continuous Deployment (CI/CD), DevOps und DevSecOps sowie AIOps.
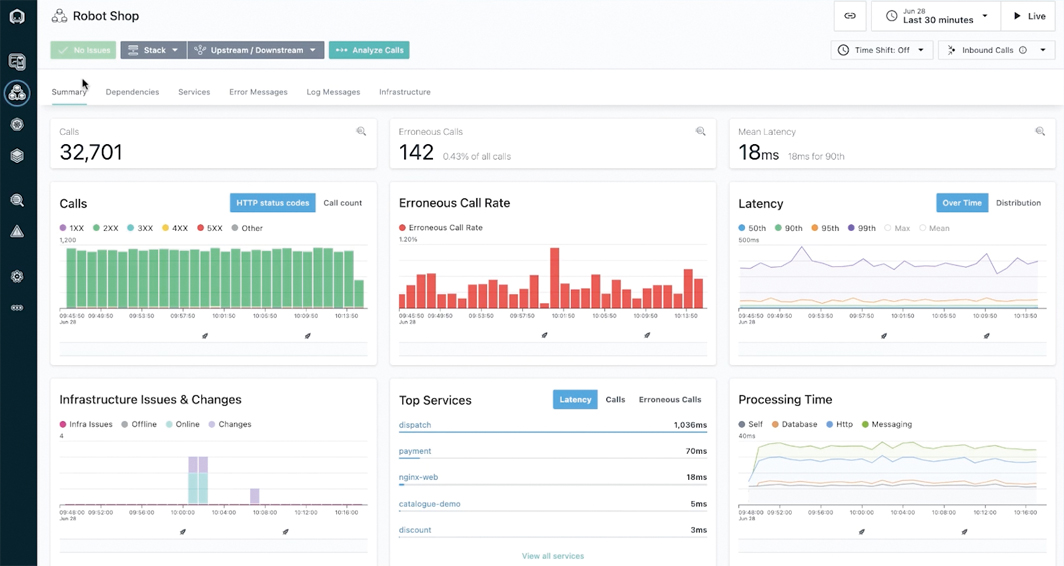
Drei Säulen: Metriken, Traces, Logs
Nach dem klassischen Modell, das im „Observability Whitepaper“ der Cloud Native Computing Foundation (CNCF) beschrieben ist, basiert Observability auf drei Säulen:
- System-Metriken
- Anwendungs-Log-Daten und
- Traces
Metriken sind numerische Messwerte, die kontinuierlich oder periodisch über eine bestimmte Zeitspanne gesammelt werden. Sie geben quantitative Einblicke in den Zustand und die Performance eines Systems und sind häufig die erste Anlaufstelle für dessen Überwachung. Beispiele sind die CPU-Auslastung (Prozessorzeit in Prozent), die Antwortzeiten eines Webservers oder einer Datenbank bei Anfragen sowie die Request-Rate (Anzahl der Anfragen pro Sekunde).
Metriken ermöglichen es, Trends zu erkennen und Abweichungen zu identifizieren. Sie machen auf Systemprobleme aufmerksam und erlauben es IT-Teams, proaktiv Gegenmaßnahmen einzuleiten, etwa wenn die Latenzzeiten bei Echtzeitanwendungen steigen. Allerdings sind Metriken häufig zu abstrakt, um spezifische Ursachen zu ermitteln.
Traces führen zu Fehlerdiagnosen
Traces wiederum bieten detaillierte Informationen über den Lebenszyklus einer Anfrage oder eines Ereignisses (Events) innerhalb eines Systems, insbesondere in verteilten Architekturen und bei Microservices. Ein Trace verfolgt den Pfad eines Requests durch Komponenten wie Web-Server, API-Gateways und Datenbanken.
Ein Beispiel ist eine http-Anfrage, die von Service A zu Service B läuft. Dabei werden alle relevanten Ereignisse und Zeitstempel erfasst. Dadurch lässt sich beispielsweise herausfinden, welche Komponenten eine zu hohe Latenz aufweisen und die Performance eines Web-Dienstes beeinträchtigen.
Log-Dateien: Basis für Ursachenforschung
Logs wiederum sind unstrukturierte oder semi-strukturierte Textnachrichten, die Systeme, Anwendungen und Dienste während des Betriebs generieren. Sie stellen detaillierte, kontextbezogene Informationen über bestimmte Ereignisse oder Aktionen innerhalb eines Systems zur Verfügung. Daher liefern Log-Daten wichtige Hinweise, welche Ursachen Fehler haben und wie sich diese beseitigen lassen. Typische Log-Daten sind Fehlermeldungen wie „Datenbankverbindung konnte nicht hergestellt werden“ oder Informationen über Systemereignisse („Web-Service A gestartet“). Auch Performance-Daten, etwa zur Dauer von Datenbank-Abfragen fallen in diese Kategorie.
Allerdings reichen die drei Säulen Metriken, Traces und Logs nicht aus, so Roman Spitzbart: „Moderne Observability-Lösungen gehen über die traditionellen Säulen hinaus, indem sie Metadaten, Benutzerverhalten, die Architektur und Code-Level-Details einbeziehen. Das ermöglicht ein ganzheitliches Verständnis und erlaubt es, proaktiv auf bekannte und unbekannte Herausforderungen zu reagieren.“
Zu diesen Herausforderungen zählt, dass in Umgebungen mit hoher Service-Komplexität und Mikroservice-Architekturen eine Veränderung an einer Stelle oft zu Problemen in einem anderen Bereich führen kann. Mithilfe von Observability-Tools lassen sich diese Abhängigkeiten nachvollziehen; Probleme können dadurch schneller isoliert und behoben werden. Das wiederum reduziert Ausfallzeiten und verkürzt die Spanne, bis Services und Anwendungen wieder zur Verfügung stehen (Mean Time to Recover / Mean Time to Repair, MTTR).
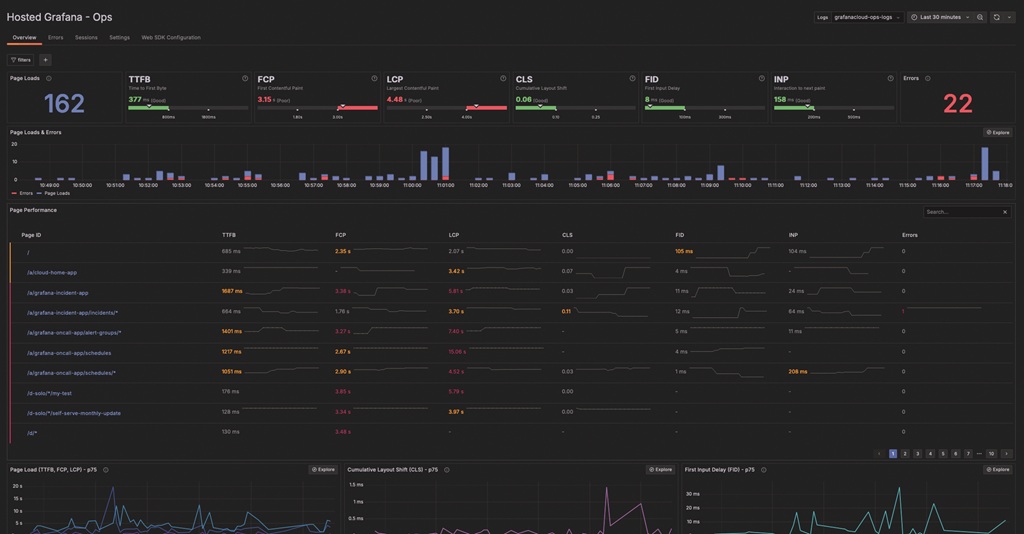
IT-Teams und Entwickler profitieren
Von Observability profitieren allerdings nicht nur die internen und externen Nutzer von IT-Ressourcen. Auch der IT-Abteilung und Software-Entwicklungsteams kann der Ansatz Vorteil bringen. Ein auf den ersten Blick trivialer Faktor: Dank der höheren Transparenz von komplexen IT-Umgebungen sind weniger Meetings nötig, bei denen Problemlösungen diskutiert werden. Weil Logs, Metriken und Traces zentral verfügbar sind, können zudem IT-Fachleute simultan an der Problemanalyse arbeiten und den Lösungsprozess beschleunigen.
Anwendungsentwickler und vor allem DevOps-Teams erhalten durch Observability-Tools wiederum Rückmeldung, ob neue Software und Apps wie erwartet „funktionieren“ – oder ob an bestimmten Stellen des IT-Stacks Probleme auftreten. Plattformen wie die von New Relic stellen zu diesem Zweck Funktionen wie ein Real-User Monitoring (RUM) bereit. Es prüft aus Sicht von Usern, also am Frontend, ob eine Software die gewünschte Performance bietet. Frontend-Entwickler haben dadurch die Möglichkeit, Probleme und deren Ursachen schneller zu diagnostizieren und zu beheben. Das wiederum kommt der Produktivität der DevOps-Teams zugute.
Anforderungen an Observability-Lösungen
Eine Observability-Lösung sollte alle Anwendungen, IT- und Cloud-Stack-Abhängigkeiten sowie Netzwerkverbindungen in Echtzeit erfassen. Hinzu kommen Automatisierungsfunktionen, um Fehler schneller zu erkennen und Lösungsoptionen bereitzustellen. Automatisierung ist laut Dynatrace unverzichtbar, um den manuellen Aufwand zu reduzieren. Weitere Funktionen, die zur Verfügung stehen sollten, sind Analysen in Echtzeit, auch von historischen Daten, und dies am besten in Verbindung mit Root-Cause-Analysen und Trendprognosen.
Ebenfalls wichtig: die Möglichkeit, andere Tools einzubinden sowie eine transparente Kostenstruktur von Tools und Plattformen. Positiv auf die Kosten wirkt sich aus, wenn ein Nutzer bei einer Plattform Observability-Funktionen für einzelne Anwendungsbereiche buchen kann, etwa für die Überwachung der Performance von Anwendungen oder im Bereich Infrastructure Observability.
Interessenten sollten zudem prüfen, ob beziehungsweise welche KI- und Machine-Learning-Funktionen die Observability-Lösung unterstützt. Beide Technologien gewinnen unter anderem deshalb an Bedeutung, weil die Datenvolumina steigen, die analysiert werden müssen. Dazu tragen im Medienbereich Trends bei wie das Streaming von Videos in UHD-Qualität (4K). Dies erhöht die Belastung der Netzwerkkomponenten und damit das Risiko, dass Fehler auftreten.
Ein beträchtlicher Teil der Anbieter von Observability-Tools und -Plattformen hat daher bereits künstliche Intelligenz und ML in seine Services integriert. Empfehlenswert ist aus Sicht von Dynatrace, dass parallel mehrere KI-Ansätze zum Einsatz kommen: „Durch die Kombination von prädiktiver, kausaler und generativer KI können wir automatisch Probleme erkennen, Ursachen analysieren und proaktive Lösungen vorschlagen“, erläutert Roman Spitzbart. „Diese KI-gestützten Funktionen steigern außerdem die Produktivität der IT-Teams, indem sie manuelle Prozesse automatisieren und datengestützte Entscheidungen erleichtern. Letztendlich führt dies zu einer verbesserten Leistung und Zuverlässigkeit der IT-Systeme unserer Kunden.“
Hürden und Fallstricke
Allerdings sollten Interessenten vor Einführung einer Observability-Lösung prüfen, welche finanziellen, technischen und organisatorischen Herausforderungen damit verbunden sind. Vor allem dann, wenn eine Plattform große und komplexe Systeme unterstützen soll, kann dies zu hohen Kosten führen. Ein Grund dafür ist, dass die Preisgestaltung etlicher Anbieter auf der Menge der gesammelten Daten basiert.
Ein weiterer Faktor ist die Komplexität bei der Implementierung. In der Praxis müssen Metriken, Logs und Traces an die Systemlandschaft und Anwendungen angepasst werden. Das erfordert spezielle Kenntnisse und kann zeitaufwendig sein. Vor allem die Einbindung von älteren „Legacy“-Systemen erfordert häufig solche Anpassungen. Und solche älteren IT-Umgebungen sind durchaus noch häufig in deutschen Unternehmen anzutreffen. Laut der Studie „Legacy-Modernisierung 2024“ von IDG Research Services / Foundry nutzt noch ein Drittel der Firmen in großem Umfang Mainframes und ältere Software für wichtige Aufgaben.
Traces wiederum bieten detaillierte Informationen über den Lebenszyklus einer Anfrage oder eines Ereignisses (Events) innerhalb eines Systems, insbesondere in verteilten Architekturen und bei Microservices. Ein Trace verfolgt den Pfad eines Requests durch Komponenten wie Web-Server, API-Gateways und Datenbanken.
Ein Beispiel ist eine http-Anfrage, die von Service A zu Service B läuft. Dabei werden alle relevanten Ereignisse und Zeitstempel erfasst. Dadurch lässt sich beispielsweise herausfinden, welche Komponenten eine zu hohe Latenz aufweisen und die Performance eines Web-Dienstes beeinträchtigen.
Zu berücksichtigen ist zudem, wie bereits angesprochen, die große Menge an gesammelten Daten. Ohne Datenstrategie und Filterfunktionen besteht die Gefahr, dass es nur mit einem hohen Aufwand möglich ist, aus dem Datenbestand verwertbare Informationen (Insights) herauszudestillieren. Das steht wiederum in Widerspruch zur Anforderung, möglichst schnell, am besten in Echtzeit, auf Anomalien und Fehler zu reagieren.
Auf einen weiteren Fallstrick weist das Softwareunternehmen Splunk im Report „State of Observability 2024“ hin. Laut der Studie setzt jedes Unternehmen im Schnitt 23 unterschiedliche Observability-Tools ein. Dies ist teilweise darauf zurückzuführen, dass neue und ältere IT-Systeme unterstützt werden müssen. Ein solcher Wildwuchs kostet jedoch unnötig Geld und führt zu einer Überlastung der IT-Experten, die diese Werkzeuge betreuen.
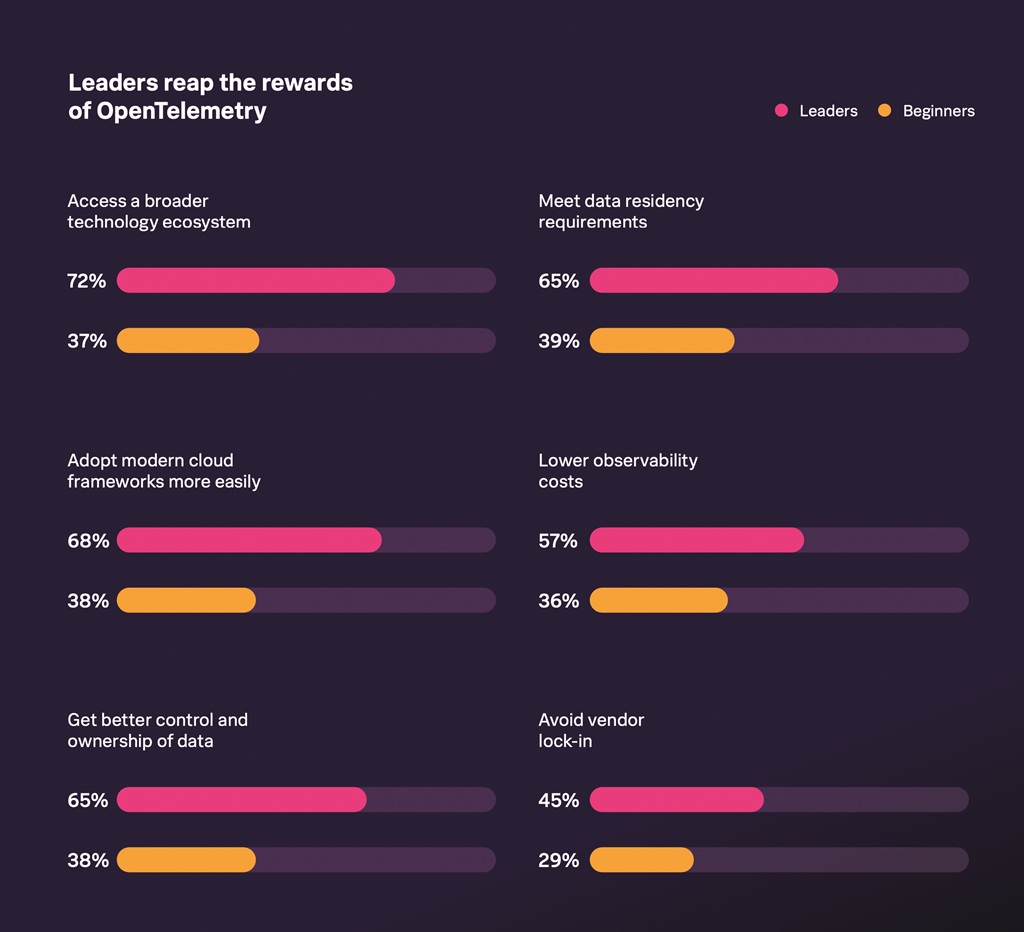
Erste Option: Do-it-yourself mit Open Source
Unternehmen, die in Eigenregie eine Observability-Umgebung aufbauen möchten, können dies mithilfe von Open-Source-Tools und Standards wie Open Telemetry tun. Ein Teil der Entwickler solcher Tools hat mittlerweile kommerzielle Spielarten auf den Markt gebracht, etwa in Form von Observability-Plattformen. Dazu zählen Prometheus und Grafana Labs.

Ein Beispiel für solche Open-Source-Anwendungen ist Prometheus. Es wurde ursprünglich von Soundcloud entwickelt und dient dazu, Metriken zu erfassen. Ein Bestandteil ist eine zeitreihenbasierte Datenbank. Mittlerweile bieten auch Cloud-Serviceprovider wie AWS, Microsoft (Azure) und Google (Google Cloud Platform) Prometheus als Managed Service an.
Grafana wiederum legt bei der Open-Source-Version seiner Observability-Plattform den Schwerpunkt auf die Visualisierung und Analyse von Metriken. IT-Spezialisten und Software-Entwickler können mithilfe von konfigurierbaren Dashboards beispielsweise die Performance von IT-Systemen und -Services sowie von Applikationen erfassen und potenzielle Schwachstellen ermitteln. Ebenfalls von Grafana Labs stammt Loki. Diese Plattform sammelt Log-Daten und ordnet sie in Zeitreihen an. Dies vereinfacht die Suche nach Auffälligkeiten. Ebenfalls auf das Sammeln, Analysieren und Visualisieren von Log-Files ist der ELK Stack (Elasticsearch, Logstash, Kibana) ausgelegt. Elasticsearch dient als Such- und Analysetool, Logstash als Pipeline für Log-Daten und Kibana zur Visualisierung. ELK Stack eignet sich vor allem für die Analyse großer Mengen unstrukturierter Daten, die häufig in Log-Dateien vorkommen.
Und noch ein Beispiel für eine Open-Source-Software für das Erfassen und Auswerten von Traces: Jaeger wurde vom Mobilitätsdienstleister Uber entwickelt. Die Plattform analysiert Traces in verteilten Systemen und Microservices. Daraus lassen sich Informationen über das Verhalten von Systemen und Applikationen ableiten, einschließlich der Ursachen für fehlerhafte Transaktionen.
Zweite Option: Plattformen statt Tools
Zu den Vorteilen von separaten Tools zählt, dass sie für einzelne Aufgaben im Zusammenhang mit Observability optimiert wurden, etwa die Analyse von Log-Dateien. Diese Funktionen erfüllen sie teilweise besser als Observability-Plattformen. Hinzu kommt der Faktor Kosten: IT-Teams oder DevOps- und AIOps-Spezialisten können nach Bedarf einzelne Werkzeuge ordern und einsetzen. Bei einer Plattform können dagegen auch Kosten für Funktionen anfallen, die Fachleute nicht benötigen.
Für eine Plattform dagegen spricht, dass sie Nutzern eine zentrale Anlaufstelle zur Verfügung stellt – in Bezug auf die Funktionen, das Datenmodell und das User Interface. Die Integration von Datenquellen und Tools sowie deren Management ist einfacher als beim Einsatz von Tools unterschiedlicher Herkunft. Dies ist angesichts der hohen Belastung von IT-Fachleuten von Vorteil.
Neben Spezialanbietern wie Dynatrace, New Relic, Datadog, Grafana und Splunk drängen zunehmend Cloud-Serviceprovider wie AWS, Microsoft und Google auf den Markt der Observability-Plattformen. Dort sind auch weitere IT-Firmen wie IBM, ServiceNow und Oracle vertreten. Für Unternehmen, die bereits Services von einem dieser IT- und Cloud-Anbieter beziehen, liegt es nahe, dies auch im Bereich Observability zu tun.
Für Unternehmen aus den Sparten Medien, TV und Streaming kommen zudem Anbieter wie Akamai und Accedo in Betracht. Akamai stellt als Ergänzung seiner Content-Delivery-Network-Dienste (CDN) auch Security- und Observability-Lösungen bereit. Es ist davon auszugehen, dass auch andere Anbieter von Observability-Lösungen solche Anwendungsfälle künftig verstärkt berücksichtigen. Dadurch können sie vom Trend in Richtung Echtzeitkommunikation profitieren, sprich Audio- und Videokonferenzen, Contact Center und Streaming.
Fazit: Observability ist mehr als ein Werkzeug
Observability wird derzeit häufig noch als Werkzeug betrachtet, um ein Fehlverhalten von IT-Systemen, Anwendungen oder Cloud-Ressourcen zu erkennen und Gegenmaßnahmen zu ergreifen. Doch das ist zu kurz gedacht, wie Roman Spitzbart feststellt: „Observability kann die entscheidende Grundlage für datenbasierte Geschäftsentscheidungen darstellen, sowohl operativ als auch strategisch.“
Doch um das zu erreichen, müssen sich Plattformen und Tools weiterentwickeln, etwa durch die Integration von Automatisierungsfunktionen und KI-gestützten Analysetools. Daher plädiert der Fachmann von Dynatrace für die Kombination von generativer KI und Observability: „Durch die Integration von GenAI werden die Analysen demokratisiert, weil sie in natürlicher Sprache für verschiedene Teams zugänglich sind, von DevOps über Security bis hin zum Business.“
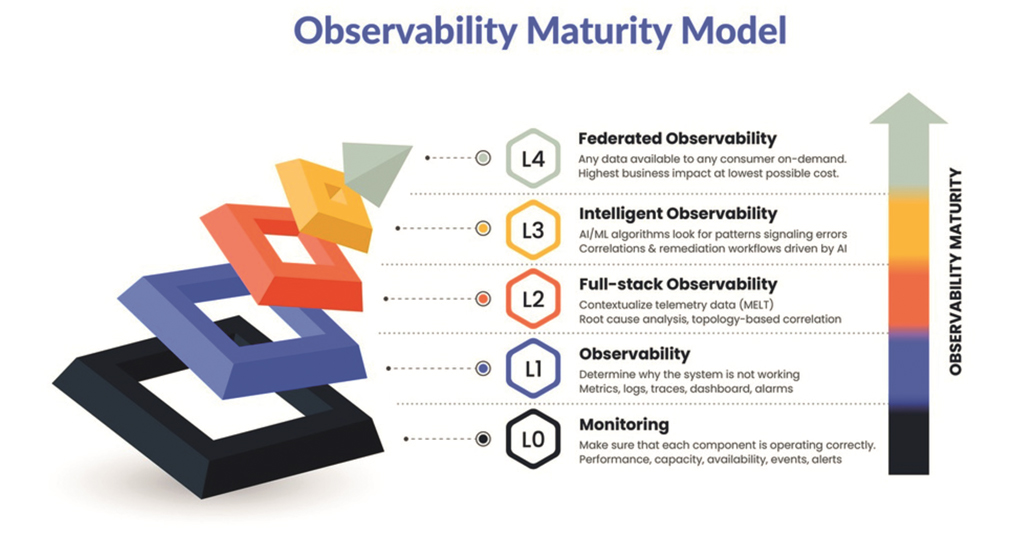
Observability vs. Monitoring
Das Monitoring von IT-Infrastrukturen, Cloud-Services und Anwendungen ist in den meisten Unternehmen ein Standardprozedere. Teilweise wird dabei aber Monitoring mit Observability gleichgesetzt. Doch es gibt klare Unterschiede:
Monitoring
Fokus: Überwachung des aktuellen Zustands eines Systems oder einer Anwendung.
Ziel: Früherkennung von Problemen und die Gewähr, dass ein System innerhalb definierter Grenzen funktioniert.
Datenquellen: Monitoring ist auf die Erfassung und Anzeige von vordefinierten Metriken ausgerichtet, etwa CPU-Auslastung, Speicherverbrauch und Response-Zeiten.
Fragen, die Monitoring beantwortet: „Ist das System gesund?“ oder „Gibt es eine Abweichung von einem festgelegten Standard?“
Typische Tools: Prometheus, Zabbix, Nagios
Observability
Fokus: Fähigkeit, den Zustand eines Systems zu verstehen und zu diagnostizieren, insbesondere von komplexen und verteilten IT-Umgebungen.
Ziel: Probleme untersuchen und deren Ursache ermitteln, ohne dass im Voraus exakt bekannt ist, wonach man suchen muss.
Datenquelle: Observability umfasst Metriken, Logs und Traces, um tiefgehende Einblicke in das Verhalten eines Systems zu erhalten.
Fragen, die Observability beantwortet: „Warum verhält sich das System auf eine bestimmte Weise?“ oder „Was ist die Folge, wenn bestimmte Fehler auftreten?“
Typische Tools: Open Telemetry, Jaeger, Grafana, ELK Stack (Elasticsearch, Logstash, Kibana)
Verwechslungsgefahr: Monitoring-Tools und Observability-Software ähneln sich zwar, doch gibt es klare Unterschiede in Zielen und Funktionen.
| Anbieter | Lösung | Einsatzfelder |
| Akamai https://www.akamai.com/de | Traffic Peak Observability Platform | Observability für Gaming- und Medieninhalte |
| Acceldata https://www.acceldata.io | Acceldata Data Observability Cloud Platform | Cloud-Plattform für Data Observability |
| Accedo https://www.accedo.tv | OTT Video Solutions; Pay TV Solutions; | Observability für TV, Pay TV und Streaming; Basis von New-Relic-Plattform |
| Actus https://actusdigital.com | Actus Intelligent Monitoring Platform | Auf TV, Audio, Streaming zuschnitten |
| Apica https://www.apica.io/ | Apica Observe | Full-Stack-Observability von Logs, Metriken, Traces, |
| BMC Software https://www.bmcsoftware.de | BMC Helix Operations Management Platform mit Helix Discovery und Netreo Network Observability | Observability-Funktionen für Netzwerke, IT-Systeme und Services |
| Chronosphere | “Chronosphere Observability Platform; Telemetry Pipeline” | Cloud-Plattform mit Support von Open-Source-Tools wie Prometheus, Jaeger und Open Telemetry; |
| Cribl https://cribl.io | Cribl Suite | Aufbau von Observability-Pipelines; Datensuche in Log-Stores, Data Lakes und auf Edge-Systemen |
| Datadog https://www.datadoghq.com/de | Datadog Platform | Monitoring von Apps, Data Streams, Services |
| Dynatrace https://www.dynatrace.de | Dynatrace Platform | Digital Experience von Usern von Services und Apps |
| Elastic https://www.elastic.co/de | Elastic Observability auf Elastic Search AI Platform | Basis: Open Telemetry; viele Datentypen unterstützt; |
| Grafana Labs https://grafana.com | u..a. Grafana Cloud Frontend Observability und Application Observability | Für Real-User Monitoring und Überwachung von Anwendungs- Performance; |
| Google https://cloud.google.com | Google Cloud Monitoring; Cloud Logging; Cloud Trace | Cloud-Services für Observability, Tracing, Monitoring, Logging |
| Honeycomb | Honeycomb Observability Platform | Log-Analyse, Telemetrie-Pipelines, Frontend-Observability |
| IBM https://www.ibm.com/de-de/ | IBM Instana Observability | Full-Stack-Observability, speziell für Application Performance Monitoring |
| Logic Monitor https://www.logicmonitor.com/lp/de | Logic Monitor Platform | Plattform für automatisierte Netzwerküberwachung, etwa im Kundenservice und Medienbereich |
| Logiz.io https://logz.io | Logz.io-Plattform mit AI Agent | KI-basierte Plattform für Observability und Log-Management; |
| Microsoft https://azure.microsoft.com/de-de | Azure Monitor | Cloud-Service; Analyse von User-Verhalten |
| New Relic https://newrelic.com/de/ | New Relic Platform | Digital Experience Monitoring, u. a. im Medien- und Unterhaltungssektor |
| Oracle https://www.oracle.com/de/ | Oracle Cloud Observability and Management Platform | Full-Stack-Observability, inklusive mit Analytics- und Automatisierungsfunktionen |
| ServiceNow https://www.servicenow.com/de | Cloud Observability | Cloud-Plattform mit KI-Funktionen für ITOps- und DevOps-Teams; Analyse von Cloud- und Standardanwendungen; |
| Splunk https://www.splunk.com/de_de | Splunk Observability Cloud; Splunk Platform | Performance von Anwendungen; User Monitoring, Log-Analyse; Lösungen von Appdynamics durch Mutterunternehmen Cisco integriert; |
| Sumo Logic https://www.sumologic.com/de/ | Sumo Logic Plattform; | Digital Experience; Log-Analyse; Infrastruktur-Monitoring; |



























































































































